sort使用不规范导致Crash问题
问题排查
最近在使用std::sort进行排序的时候遇到一个crash问题,一开始摸不着头脑,花了一番功夫才找到原因。
背景是音视频通信的媒体服务端在和客户端建立媒体通道时,往往会有多条连接作为主备连接,应对不同网络情况,例如同时有5G、WIFI等多路连接。这些连接一般都是由客户端通过发送STUN协议的UDP包发起的。
当客户端建立的连接数超过限制时,服务端需要枝剪多余连接,枝剪的逻辑需要通过对比连接质量等一系列条件来排序决定。C++标准库已经为我们实现性能优异的std:sort,通常也没人会去挑战STL,这里我也直接就用了。代码片段如下:
void P2PTransportChannel::PruneConnections2() {
std::map<rtc_base::IPAddress, std::vector<Connection*>> conns_map;
//... insert map
for (auto pair : conns_map) {
// sort connections
std::sort(pair.second.begin(), pair.second.end(), [this](Connection* a, Connection* b) {
return CompareConnectionCandidates(a, b) >= 0;
});
}
}
这里sort传入一个闭包,闭包里调用CompareConnectionCandidates方法比较两条连接的优先级(因为两条连接可能优先级相等,所以用了>=,这也为后面的crash埋下了伏笔)。
代码乍一看好像没啥问题,上线前自测和QA测试也都正常。然而版本上线后,线上却出现了多例crash,coredump在了比较方法中,而且有个特点是connection连接数都比较多;
从crash堆栈看到参与比较的两个Connection指针a=0x87a804feff3e1602,b=0x4bc4a00,这里a的指针异常大:
#0 0×00007f849b8cbbf1 in ice::P2PTransportChannel::CompareCandidatePairNetworks (ice::Connection const*, ice::Connection const*, rtc_base::optional<rtc_base::AdapterType>) const (this=0xd0c1400, a=0×87a804feffe1602, b=0x4bc4a00, network_pr eference=...) at ../../../../core/pc/transport/ice/ice/p2p_transport_channel.cc:1629
#1 0x00007f849b8cbdab in ice::P2PTransportChannel::CompareConnectionCandidates (ice::Connection const*, ice::Connection const*) const (this=<optimized cut >, a=0x87a804feff3e1602, b=0x4bc4a00) at ../../../../core/pc/transport/ice/ice/p2p_transport_channel.cc:1731
#2 0x00007f849b8cc0df in ice::P2PTransportChannel::<lambda(ice::Connection *, ice::Connection*)>::operator() (b=<optimized out>, a=<optimized out>, closure=<synthetic pointer>) at ../../../../core/pc/transport/ice/ice/p2p_transport_channel.cc:1996
#3 0x007849b8ccodf in _gnu_cxx_opsTter_cop_itercdin_ice:PPTransportChannel::PruneConnections2()::<lambda(ice::Connection*, ice::Connection*)>>::operator()<_gnu_cxx::_normal_iteratorșice::Connection**, std::vector<ice::Connection*>>,_gnu_cxx::_normal_iterator<ice::Connection**, std::vector<ice::Connection*>>>(it2=0x4bc4a00, _it1=..., this=<synthetic pointer>) at /opt/rh/devtoolset-7/root/usr/include/c++/7/bits/predefined_ops.h:143
#4 0×00007f849b8ccodf in std::_unguarded_partitions_gnu_cxx::_normal_iterator<ice::Connection**, std::vector<ice::Connection*>>,_gnu_cxx::_ops::_Iter_comp_iter<ice::P2PTransportChannel::PruneConnections2()::<lambda(ice::Connection*, ice::Connection*)>>>(_comp=..., _pivot=0x4bc4a00, _last=0×87a804feff3e1602, _first=0x87a804feff3e1602) at /opt/rh/devtoolset-7/root/usr/include/c++/7/bits/stl_algo.h:1902
为了进一步确认,继续通过反汇编查看crash附近代码执行情况。可以看到崩溃行所在地方是从rsi访存写入rax寄存器,很可能是bad access了:
0x00007f849b8cbbf0 <+0>: push %rbp
=> 0x00007f849b8cbbf1 <+1>: mov 0x150 (%rsi),%rax
继续查看内部寄存器状态:
info register
rax 0×0 0
rbx 0x5f8cd78 100191608
rcx 0×7f849e4b2db8 140207568137656
rdx 0×4bc4a00 79448576
rsi 0×87a804feff3e1602 -8671675589251426814
rdi 0×d0c1400 218895360
rbp 0×7f849e4b2de0 0×7f849e4b2de0
rsp 0×7f849e4b2da0 0×7f849e4b2da0
果然,rsi寄存器存放的Connection指针地址异常了。但是这里我们用的标准库进行遍历的,vector对象也在栈上,难道vector内部成员被篡改了?
继续查看vector对象,一共17个成员,Connection指针地址也没有问题。难道是vector::end()返回的地址有问题?
p pair.second
$3 = std::vector of length 17, capacity 17={0×4bc4a00, 0xfb5de00, 0xf43c400, 0xf43a0, 0xef7400, xf43be00, 0xf3b000, xf43000, xf3bde00,0x1b800, xef73, fb5e400, 0xf3bf600, 0xf3bc600, 0x11b26000, 0xe18e000, 0x11b27e00}
继续查看vector内部结构题__M_impl。其中__M_start指向容器中第一个元素的指针,__M_finish指向容器最后一个有效元素的下一个位置的指针,end()方法返回的就是__M_finish。
p pair.second._M_impl
$2={<std::allocator<ice::Connection*>>={<_gnu_cxx::new_allocator<ice::Connection*>>={<No data fields>}, <No data fields>}, M_start =0x5f8ccf0, _M_finish =0x5f8cd78, _M_end_of_storage = 0x5f8cd78}
M_finish = 0x5f8cd78,这个地址看起来也没问题。既然拿到了内存地址,我们可以进一步分析下里面存的到底是什么:
x /8xg 0x5f8ccf0
0x5f8ccf0: 0x0000000004bc4a00 0x000000000fb5de00
0x5f8cd00: 0x000000000f43c400 0x000000000f43ac00
0x5f8cd10: 0x000000000ef74a00 0x000000000f43be00
0x5f8cd20: 0x000000000f3bc000 0X000000000f43a000`
x /8xg 0x5f8cd30
0x5f8cd30: 0x000000000f3bde00 0x0000000011b27800
0x5f8cd40: 0x000000000ef73800 0x000000000fb5e400
0x5f8cd50: 0x000000000f3bf600 0x000000000f3bc600
0x5f8cd60: 0x0000000011626000 0x000000000e18e000
x /8xg 0x5f8cd70
0x5f8cd70: 0x0000000011b27e00 0x87a804feff3e1602
0x5f8cd80: 0x0000000005f8ce10 0x0000000000000000
0x5f8cd90: 0x0000000100000005 0x0000000000000001
0x5f8cda0: 0x0000000000000000 0x0000000100000005
这里我们用x/8xg 查看内存地址。8代表要显示的内存单元数量,x表示16进制,g表示读取8字可以看到异常值0x87a804feff3e1602在内存地址0x5f8cd78处。这个地址对应__M_finish,是结束的地方,按道理sort排序不可能会访问到这个地址。但是出错的堆栈又实实在在指向了这个地址,一时间没有了思路。
std::sort实现
没办法,只能尝试从源码入手,看看能不能有线索。通过分析代码和查阅资料,了解到gcc7的sort实现采用了混合排序,包含了插入排序、快速排序、桶排序三种排序算法,目的是为了综合各种排序算法的优点:
-
在数据量很大时采用正常的快速排序,此时效率为O(logN)。
-
一旦分段后的数据量小于某个阈值,就改用插入排序,因为此时这个分段是基本有序的,这时效率可达O(N)。
-
在递归过程中,如果递归层次过深,分割行为有恶化倾向时,它能够自动侦测出来,使用堆排序来处理,在此情况下,使其效率维持在堆排序的O(N IogN),但这又比一开始使用堆排序好。
实现代码如下:
template<typename _RandomAccessIterator, typename _Compare>
inline void
_sort(_RandomAccessIterator _first, _RandomAccessIterator _last, _Compare _comp)
{
if (_first!= _last)
{
std::_introsort_loop(_first, _last, _comp); // 内省式排序
std::lg(_last - _first) * 2; // 计算复杂度
std::_final_insertion_sort(_first, _last, _comp); // 插入排序
}
}
这里是一个函数模版,包含了两个调用,std:introsort_loop是排序算法主体,std::final_insertion_sort则是插入排序;
先来看__introsort_loop:
template<typename _RandomAccessIterator, typename _Size, typename _Compare>
void
_introsort_loop(_RandomAccessIterator _first, _RandomAccessIterator _last, _Size _depth_limit, _Compare _comp)
{
while (_last - _first > int(_S_threshold)))// 数量大于_S_threshold(16),使用快速排序
{
if (_depth_limit == 0)
{
std::_partial_sort(_first, _last, _last, _comp);// 深度>0,使用桶排序
return;
}
--_depth_limit;
_RandomAccessIterator _cut = std::_unguarded_partition_pivot(_first, _last, _comp);
_last = _cut;
std::_introsort_loop(_cut, _last, _depth_limit, _comp);
}
}
注意只有当vector的数量超过__S_threshold(16)时,才会导致进入快速排序;否则,直接跳出循环(执行final__insertion_sort插入排序)。快速排序在while循坏体中,这里有一定的技巧性,调用unguarded__partition_pivot的返回值cut是pivot右半部分,之后再pivot左半部分继续调用introsort__loop,这样做可以减少函数调用次数。
接下来我们继续查看__unguarded_partition_pivot主体函数:
template<typename _RandomAccessIterator, typename _Compare>
inline _RandomAccessIterator
_unguarded_partition_pivot(_RandomAccessIterator _first, _RandomAccessIterator _last, _Compare _comp)
{
_RandomAccessIterator _mid = _first + (_last - _first) / 2;
std::_move_median_to_first(_first, _first + 1, _mid, _last - 1, _comp);
return std::_unguarded_partition(_first + 1, _last, _first, _comp);
}
主体分为两个方法,move_median_to_first的作用是从首部+1、尾部和中部三个元素的取中值作为pivot,避免可能出现快速排序的复杂度最差情况O(N?)。注意这里会调用comp比较函数进行比较和swap操作,把中间值交互到首部:
template<typename _Iterator, typename _Compare>
void
_move_median_to_first(_Iterator _result, _Iterator _a, _Iterator _b, _Iterator _c, _Compare _comp)
{
if (_comp(_a, _b))
{
if (_comp(_b, _c))
std::iter_swap(_result, _b);
else if (_comp(_a, _c))
std::iter_swap(_result, _c);
else
std::iter_swap(_result, _a);
}
else if (_comp(_a, _c))
std::iter_swap(_result, _c);
else if (_comp(_b, _c))
std::iter_swap(_result, _b);
else
std::iter_swap(_result, _b);
}
__unguarded_partition方法就是我们平常所使用的快速排序主体部分:
template<typename _RandomAccessIterator, typename _Compare>
_RandomAccessIterator _unguarded_partition(_RandomAccessIterator _first, _RandomAccessIterator _last, _RandomAccessIterator _pivot, _Compare _comp)
{
while (true)
{
while (_comp(_first, _pivot))
++_first;
while (_comp(_pivot, _last))
--_last;
if (!(_first < _last))
return _first;
std::iter_swap(_first, _last);
++_first;
}
}
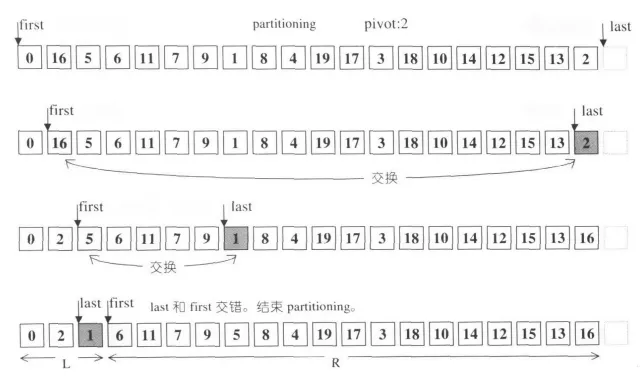
这里不多做解释,《STL源码剖析》给出了两个非常直观的示意图:
分割示例一
分割示例二
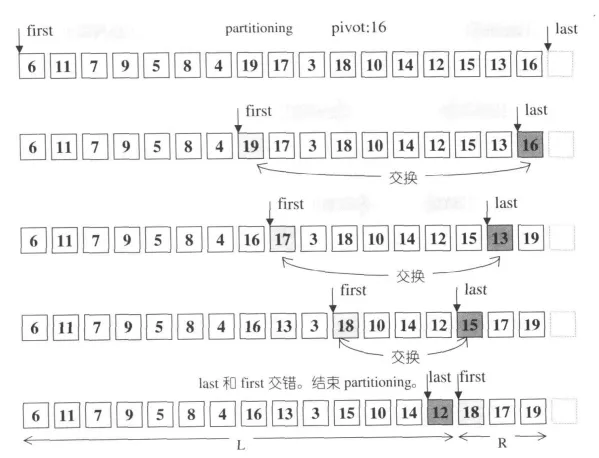
方法名unguarded和代码里的while循环引起了我的警觉,这个函数没有对first和last作边界检查,而是以两个指针交错作为中止条件,节约了比较运算的开支。可以这么做的理由是因为,选择是首尾中间位置三个值的中间值作为pivot,因此一定会在超出此有效区域之前中止指针的移动(前提是comp条件不能相等)。
这里comp(first, pivot)如果是true,first会一直循环递增。我们的业务逻辑中,比较元素Connection是可能相等的。这里极有可能是first累加越界了,其地址也能和崩溃的地址对上。
如果是这个原因的话,我们就好验证了。写一段测试代码,放入大于__S_threshold(16)个相同元素,看看会不会崩溃。
#include <iostream>
#include <map>
#include <vector>
#include <algorithm>
struct Connection {
int val = 0;
};
bool compare(Connection* a, Connection* b) {
return a->val >= b->val;
}
int main() {
std::map<int, std::vector<Connection*>> conn_map;
for (int i = 0; i < 17; i++) {
Connection* c = new Connection{1};
conn_map[1].push_back(c);
}
for (auto& pair : conn_map) {
std::sort(pair.second.begin(), pair.second.end(), compare);
}
std::cout << "ok:" << conn_map[1].size() << std::endl;
return 0;
}
使用gcc7编译运行,果然出现崩溃了:
$./a. out
2 Segmentation fault (core dumped)
而将17改为16之后,结果就不崩溃了:
$./a.out
2 ok: 16
到这里,问题原因算是找到了。这也解释了为什么自测和QA难以发现,只有线上连接数多的时候才出现。回过头来查阅文档,上面写的很明白,sort的comp函数必须严格满足严格弱序(strict weak order):
Establishes strict weak ordering relation with the following properties:
- For all a, comp(a, a) == false.
- If comp(a, b) == true then comp(b, a) == false.
- if comp(a, b) == true and comp(b, c) == true then comp(a, c) == true.
看来还是使用的姿势不对,修复就好办了,我们把判断条件中的=去掉,这下也正常了:
$./a.out
2 0k:17
总结
-
std::sort实现混合了多种排序算法,当元素数量超过16个,会使用快速排序,不会进行边界检查;
-
std::sort的comp函数必须严格满足严格弱序,如果比较元素相等,可能会导致crash问题;
-
如果比较元素可能相等,想要结果保持稳定,使用std::stable_sort代替std::sort;
参考: https://feihu.me/blog/2014/sgi-std-sort/